Ideia #3 Embeddings
🧠 Embeddings na prática: classificando comentários com um “GPS de ideias”
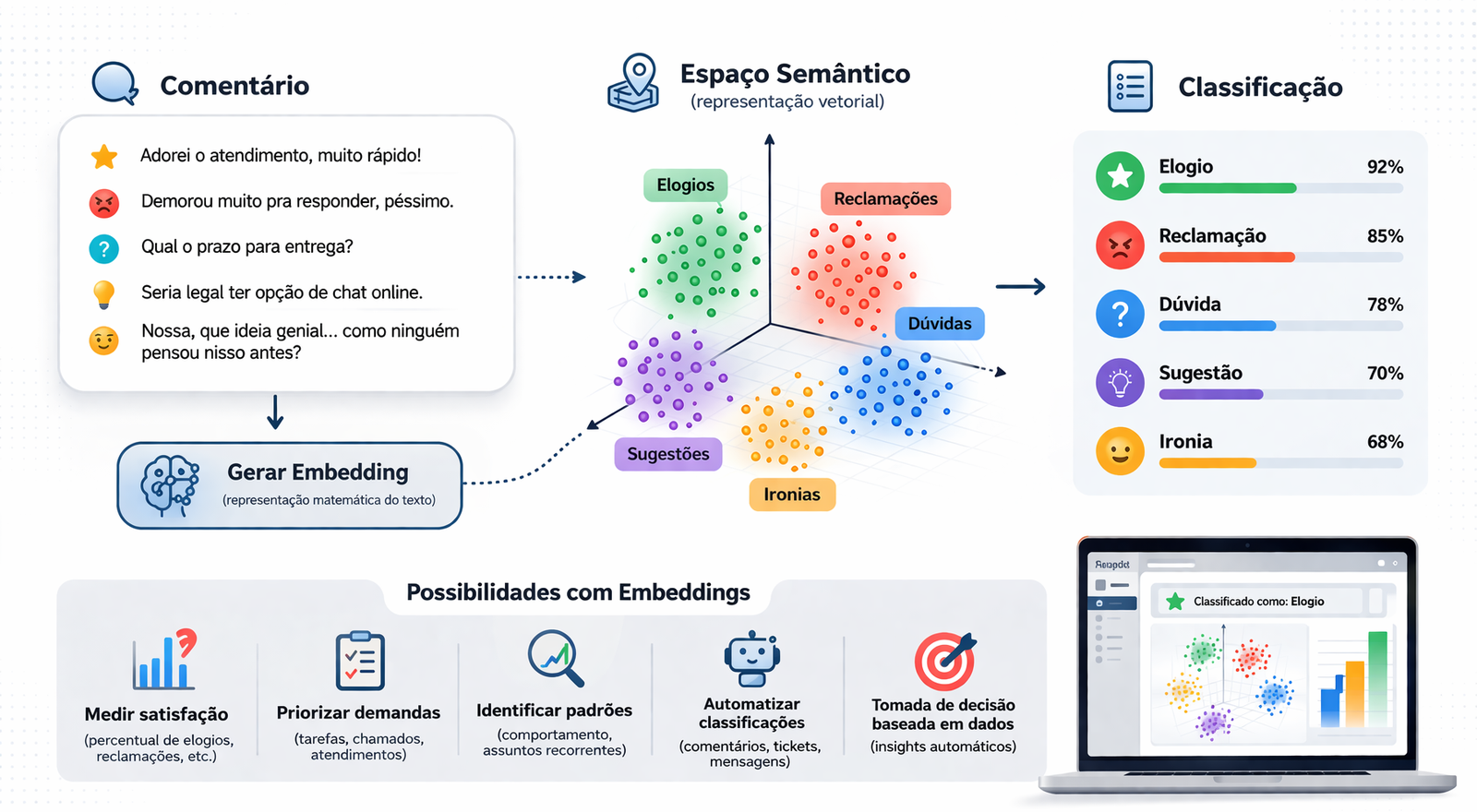
Nos últimos dias, desenvolvi uma pequena demonstração para explorar um conceito que tem ganhado bastante espaço na área de inteligência artificial: embeddings.
A ideia foi simples:
👉 pegar comentários do dia a dia e tentar classificá-los automaticamente com base no seu significado, não apenas nas palavras.
Se fosse resumir em uma frase:
Embeddings funcionam como um GPS de ideias: eles posicionam textos próximos uns dos outros quando têm significados semelhantes.
🚀 1. Treinamento prévio (base de referência)
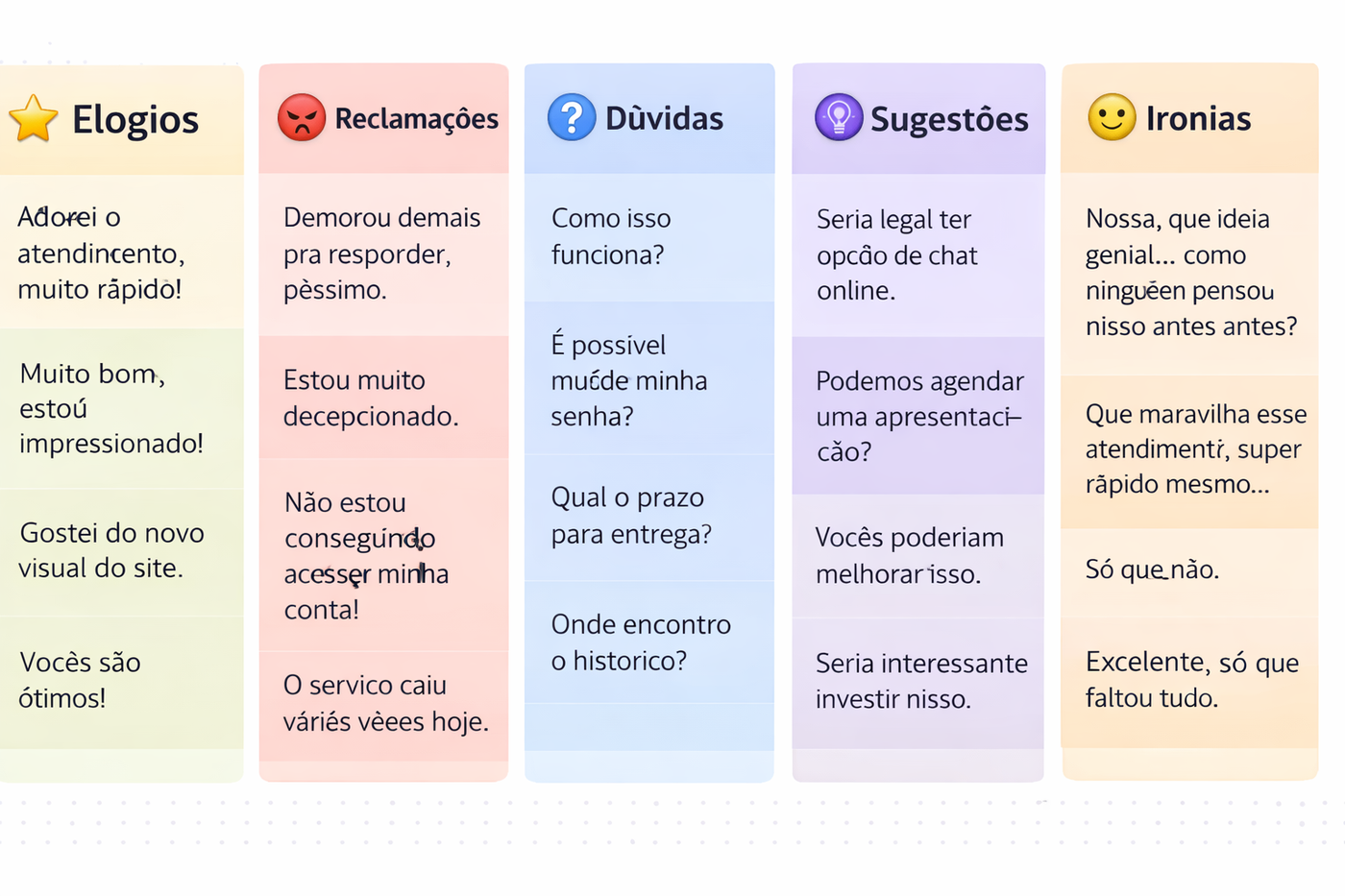
Para começar, criei uma base simples com 200 frases.
Essas frases foram distribuídas em 5 categorias:
- elogio
- reclamação
- dúvida
- sugestão
- ironia
Cada categoria recebeu cerca de 40 exemplos, com frases curtas e naturais, como:
- “Adorei o atendimento, muito rápido!”
- “Demorou demais pra responder”
- “Como isso funciona?”
- “Vocês poderiam melhorar isso”
- “Nossa, que ideia genial…”
💡 Essa base funciona como um “ponto de referência” para o sistema.
⚙️ 2. Estrutura simples (e propositalmente leve)
Como a proposta é demonstrativa, optei por uma arquitetura bem leve:
- Python
- armazenamento local com FAISS (faiss-cpu)
- embeddings gerados via API
Nada de infraestrutura pesada, para manter tudo simples e funcional.
🧠 Sobre os embeddings
Utilizei o modelo:
text-embedding-3-small
Cada texto é transformado em um vetor com cerca de 1.500 dimensões.
Mas o que isso significa?
👉 Pense assim:
- cada frase vira uma lista de números
- cada número representa uma “característica semântica”
- quanto mais parecidos dois textos são, mais próximos esses vetores ficam
💡 É como se cada texto ganhasse uma posição em um espaço multidimensional.
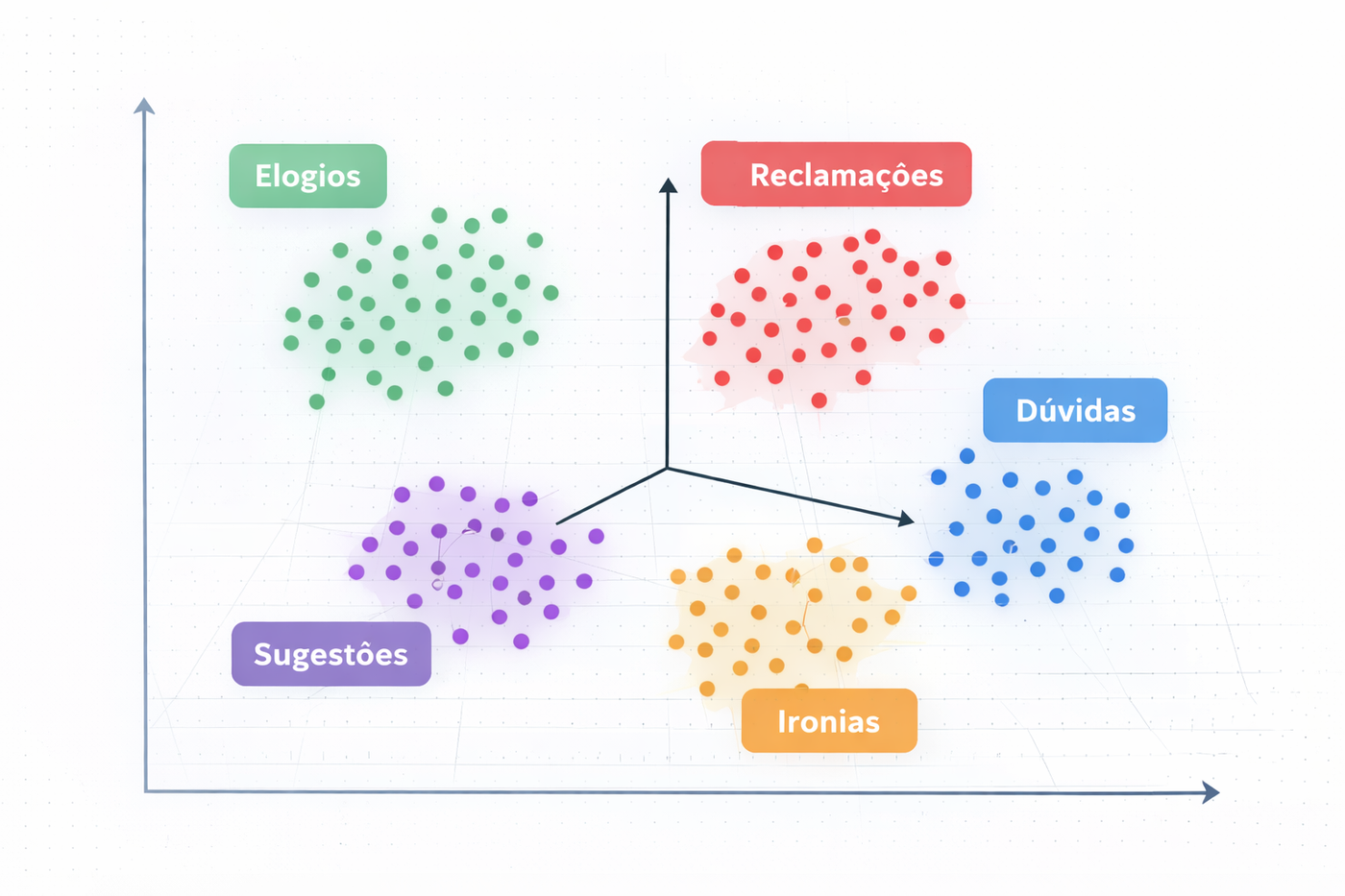
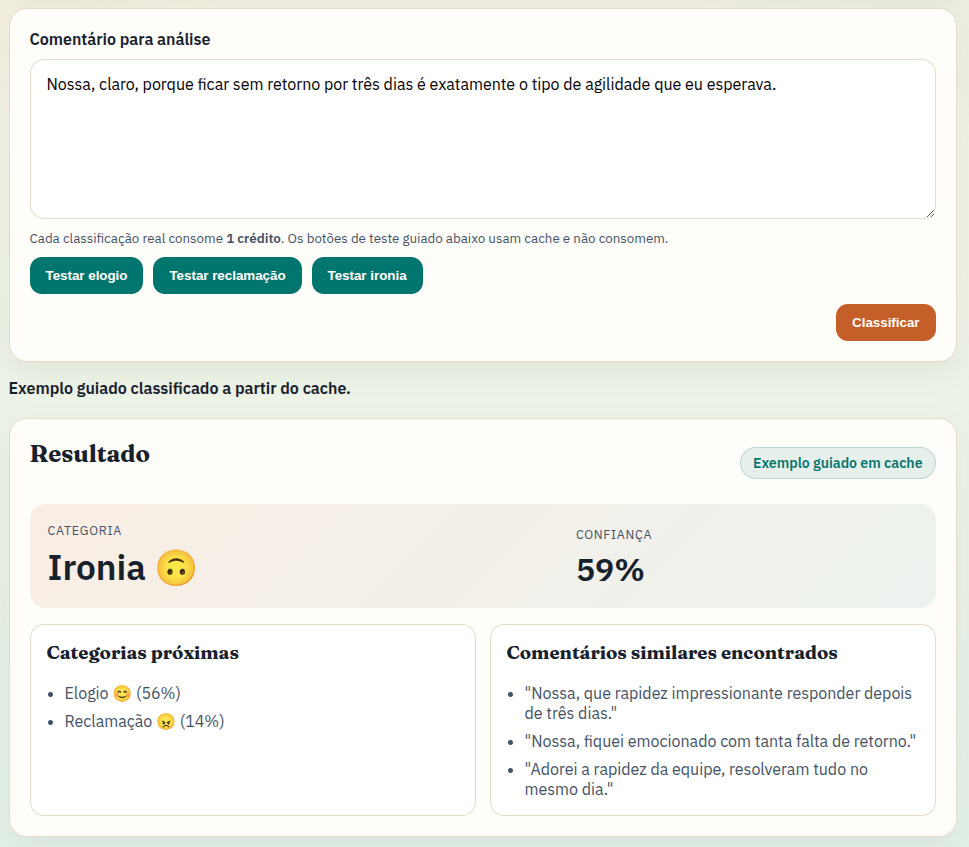
🧪 3. A experiência: testando na prática
A interface da demonstração é bem direta:
👉 Você digita um comentário curto
👉 O sistema gera o embedding desse texto
👉 E compara com os exemplos existentes
Exemplo:
"Demorou muito pra responder"
O sistema identifica quais exemplos são mais parecidos e retorna algo como:
- Reclamação (alta similaridade)
- Sugestão (moderada)
- Dúvida (baixa)
📐 4. Como funciona a comparação?
Aqui entra um conceito matemático interessante:
👉 similaridade de cosseno
Sem entrar muito na matemática:
- cada texto é um vetor
- o sistema mede o “ângulo” entre esses vetores
- quanto menor o ângulo, mais parecidos eles são
💡 Sim, eu lembrei e você também:
“Talvez a gente não use Bháskara no dia a dia… mas o cosseno está presente em nossas vidas.”
🔍 5. Mais do que classificação
Classificar é só o começo.
Uma vez que você consegue organizar textos por significado, surgem várias possibilidades:
- 📊 medir satisfação (elogios vs reclamações)
- 📌 identificar padrões recorrentes
- 🧭 priorizar demandas
- 💡 gerar insights automaticamente
🧩 Aplicações no cotidiano
Esse tipo de abordagem pode ser usado em vários contextos:
- organizar tarefas por prioridade
- classificar mensagens automaticamente
- melhorar buscas
- agrupar conteúdos semelhantes
🎯 Conclusão
Essa demonstração é simples de propósito — mas ilustra bem uma mudança importante:
👉 estamos evoluindo de sistemas que entendem palavras
👉 para sistemas que entendem significado
E quando isso acontece, abre-se um leque enorme de possibilidades.
🧪 Teste você mesmo
Disponibilizei uma versão da demonstração para testes.
👉 Você pode acessar e experimentar com seus próprios comentários.
👉 Acesse a aplicação em: https://moutinho.dev/apps/classificador-sentimentos/
📌 Utilize o usuário e senha desta imagem.

💬 Vamos trocar ideias?
Se você quiser discutir aplicações, sugerir melhorias ou trocar experiências, fico à disposição.
Essas pequenas experimentações costumam abrir portas para soluções bem interessantes no dia a dia.
Comentarios
Voltar para artigosAinda nao ha comentarios neste artigo.
Deixe seu comentario